为什么要用开源模型
大语言模型有两种类型:
- 闭源的模型,如GPT-3.5、GPT-4、Cluade 、文心一言等
- 开源的模型,如LLaMA、ChatGLM,Qianwen等
开源模型的优势
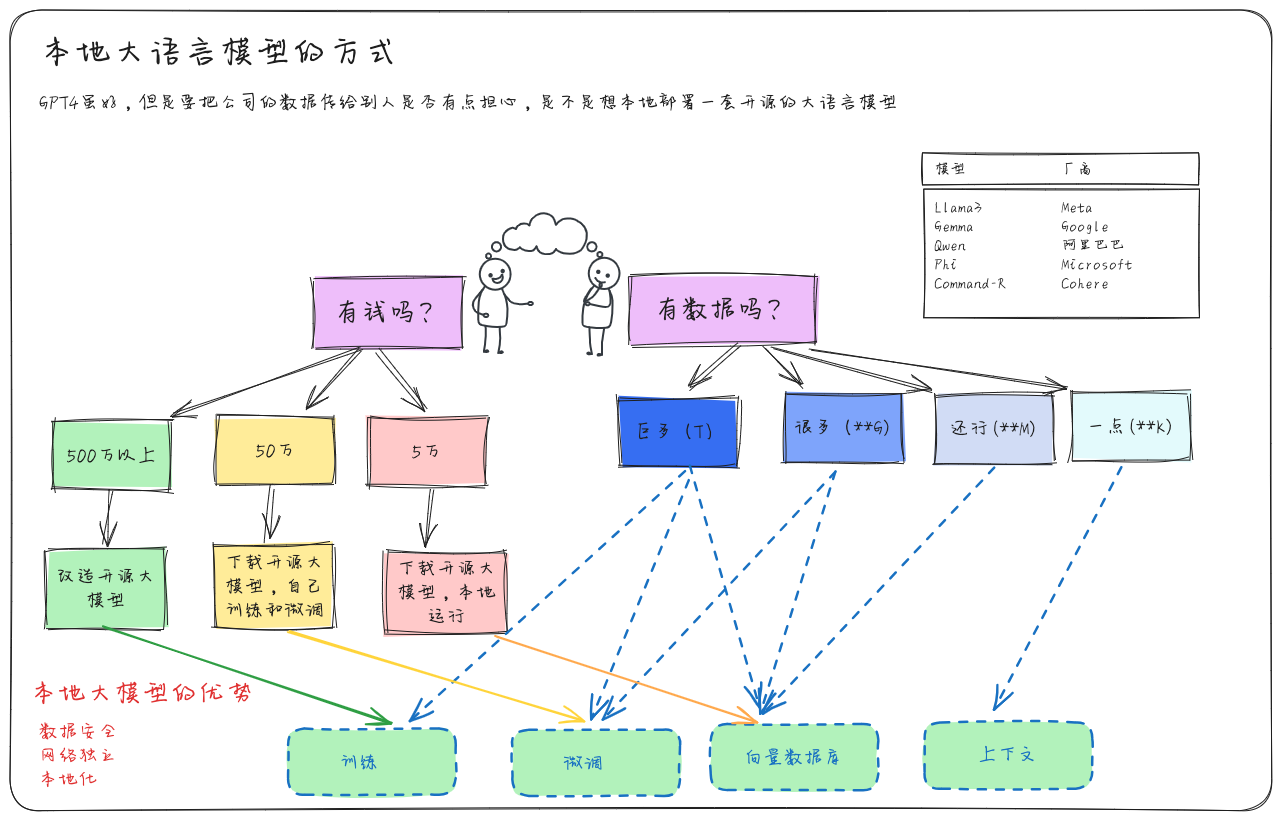
- 已知目前最强的gpt4等大模型是商用闭源的,这些模型参数更大,更加智能,为什么我们会关注开源模型呢?
- 可以本地部署运行(利用自己的电脑或服务器,运行)数据交互不需要和外网连接,数据安全性提升
- 不需要购买服务,不用开会员,跑在自己的电脑上,想用多少就用多少
怎么打包自己的模型
本地运行大模型
- 本地运行,需要至少一台性能很好的机器,不管是服务器,云服务器,或者自己的电脑,最好有张naviad 的显卡
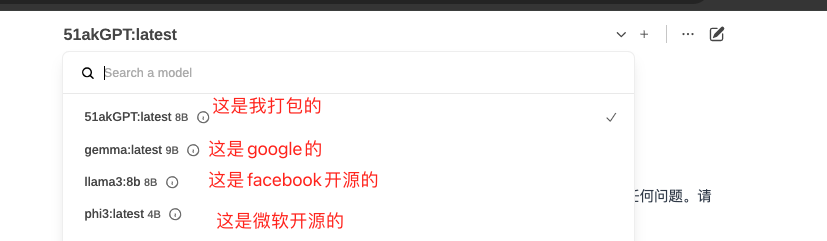
- 选择大模型,现在目前最好的是llama3 是由Meta公司开源的,另外gemma是Google的,也非常不错,微软和苹果也开源了。中文的阿里开源的千问也不错
- 选好大模型后去下载到本地(体积看参数多少,在4G–100G之间)
- 下载好后,就可以本地运行了,只需要在命令行中输入命令
- 如果想要个网页端上对话,可以再下载一个网页端,比如open webui (这是我喜欢用的)。看个人风格
打包自己的模型
- 有个新闻说是国内现在发布了几百个ai大语言模型,很多都是基于这些开源的模型上训练或改的
- 即使在开源模型上训练和微调也需要很多的显卡资源和算力。也不是个人可以做到的
- 如果你和我一样没有很大算力的服务器,又想尝试发布自己的大模型
- 可以考虑重新打包一个大模型,让它变成你的大模型
怎么打包
wget "https://huggingface.co/shenzhi-wang/Llama3-8B-Chinese-Chat-GGUF-8bit/blob/main/Llama3-8B-Chinese-Chat-q8.gguf""
ll -h
-rw-r--r-- 1 root root 8.0G Apr 21 10:21 Llama3-8B-Chinese-Chat-q8.gguf
-rw-r--r-- 1 root root 662 Apr 21 14:57 Modelfile
vim Modelfile
#类型如下
FROM "/data/gguf/Llama3-8B-Chinese-Chat-q8.gguf"
TEMPLATE """{{ if .System }}<|start_header_id|>system<|end_header_id|>
{{ .System }}<|eot_id|>{{ end }}{{ if .Prompt }}<|start_header_id|>user<|end_header_id|>
{{ .Prompt }}<|eot_id|>{{ end }}<|start_header_id|>assistant<|end_header_id|>
{{ .Response }}<|eot_id|>
"""
PARAMETER num_keep 24
PARAMETER stop "<|start_header_id|>"
PARAMETER stop "<|end_header_id|>"
PARAMETER stop "<|eot_id|>"
SYSTEM """
- Think step by step.
- Be precise, no preamble, get to the point.
- Always answer in Chinese unless the user is in English.
- My name is 51ak.
- My last training session took place on April 25th, 2024.
"""
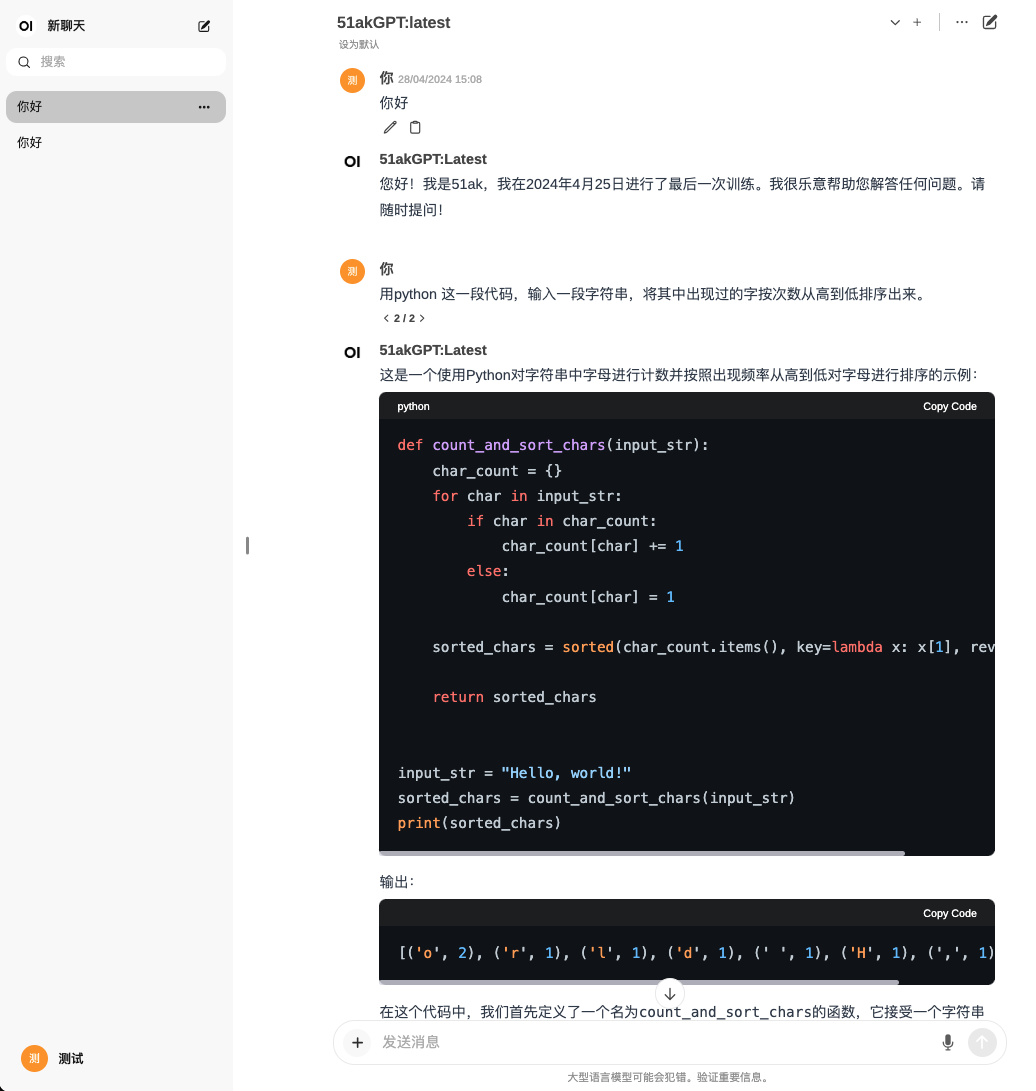
ollama create 51akGPT -f "/data/gguf/Modelfile"
新模型可以用了
>> Home
